























")










")
OVERVIEW
Splunk is a software application for normalizing or aggregating a huge amount of data in and centralized management, is a process or technique for collecting or managing the log source across various platforms like Desktops, Network devices, and even IoT devices, The main focus is to collect machine data from various sources and to add intelligence searchable head.
SPLUNK in Cyber Incident Response
Cybersecurity always required real-time monitoring to identify or detect an adversary intrusion, in such cases we need a powerful tool whose major work is to collect data across various environments and to add searchable intelligence.
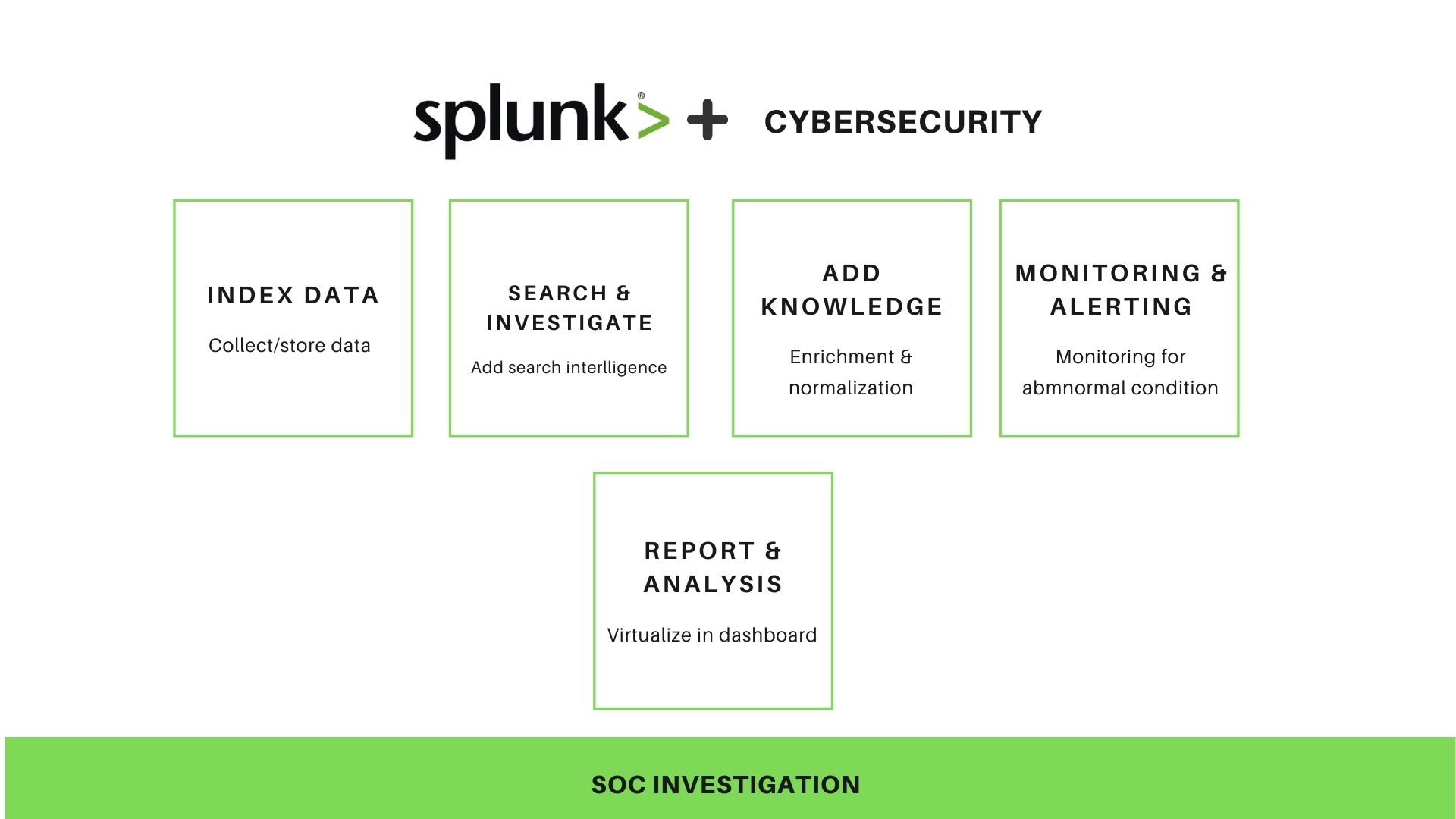
Data collection is a systematic approach to gather information from various sources to get a complete and accurate picture. Some experts reveal that “Detecting undesirable behavior can be achieved through regular monitoring”.
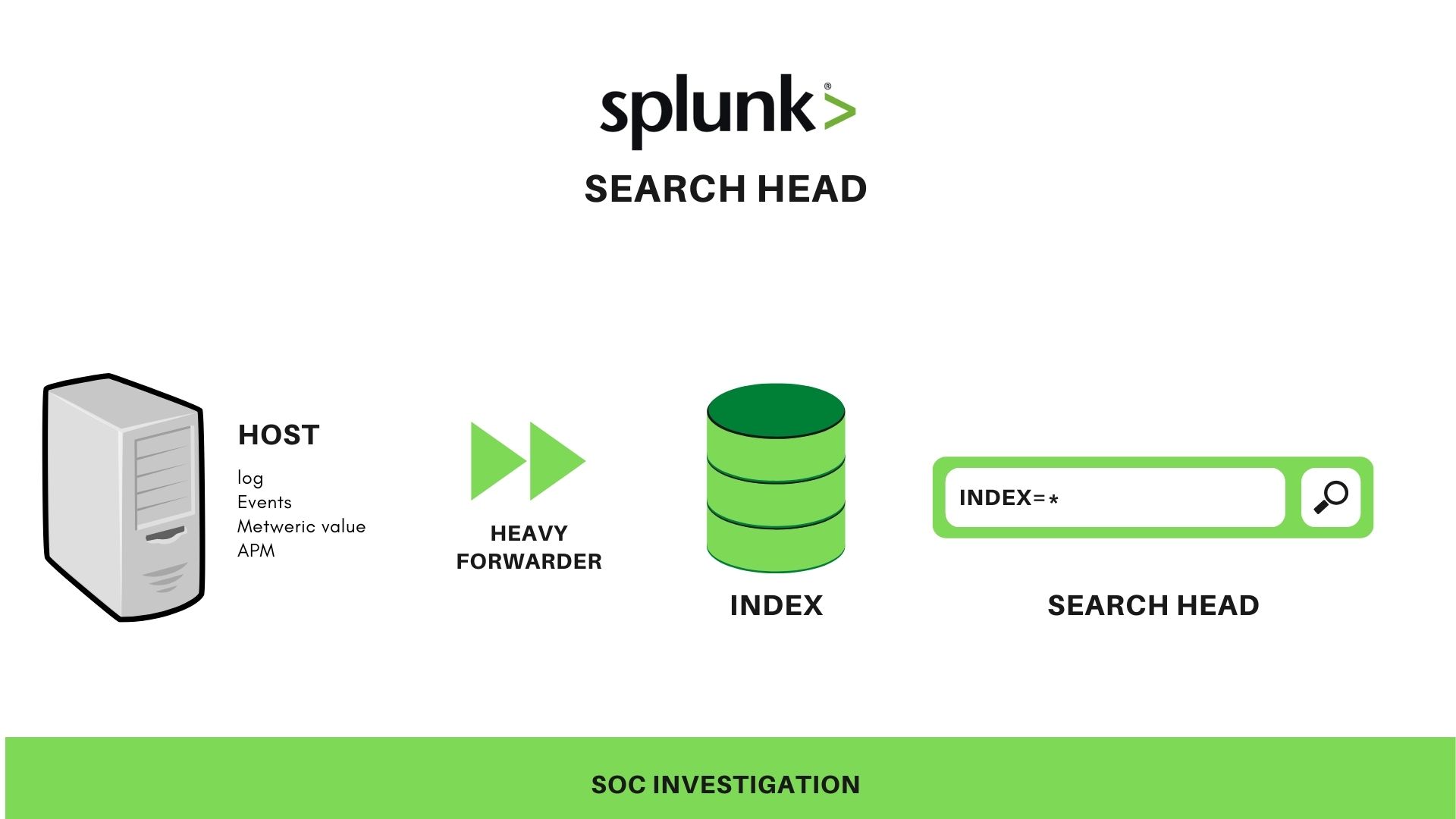
Components of SPLUNK
Three main components of Splunk:
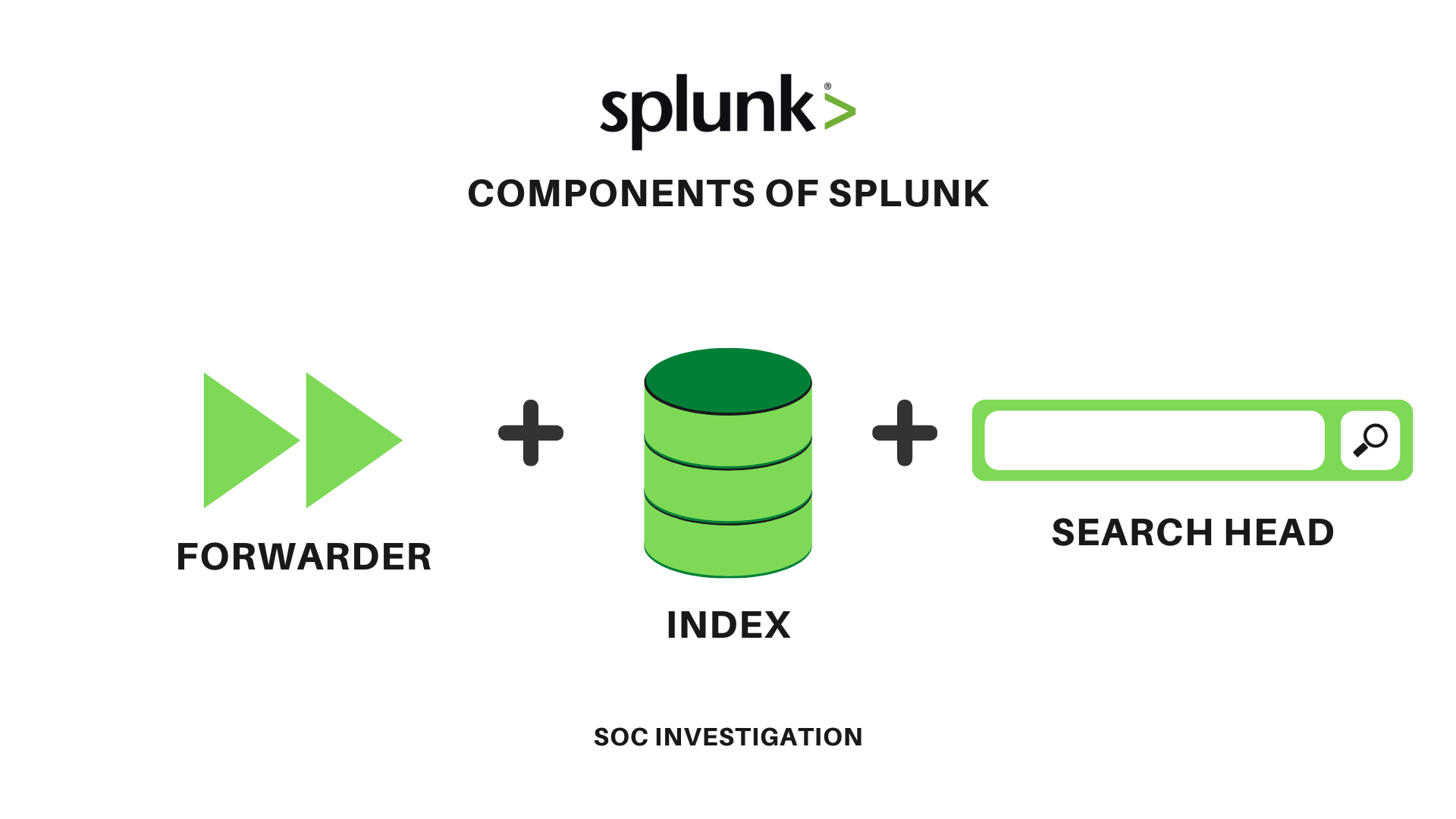
- Splunk forwarder
- Splunk index
- Search Head
Also Read: Threat Hunting using Sysmon – Advanced Log Analysis for Windows
SPLUNK Forwarder
A software component which used to forward data/log from the host machine to the indexer usually pushes the log to a centralized storage unit [index]
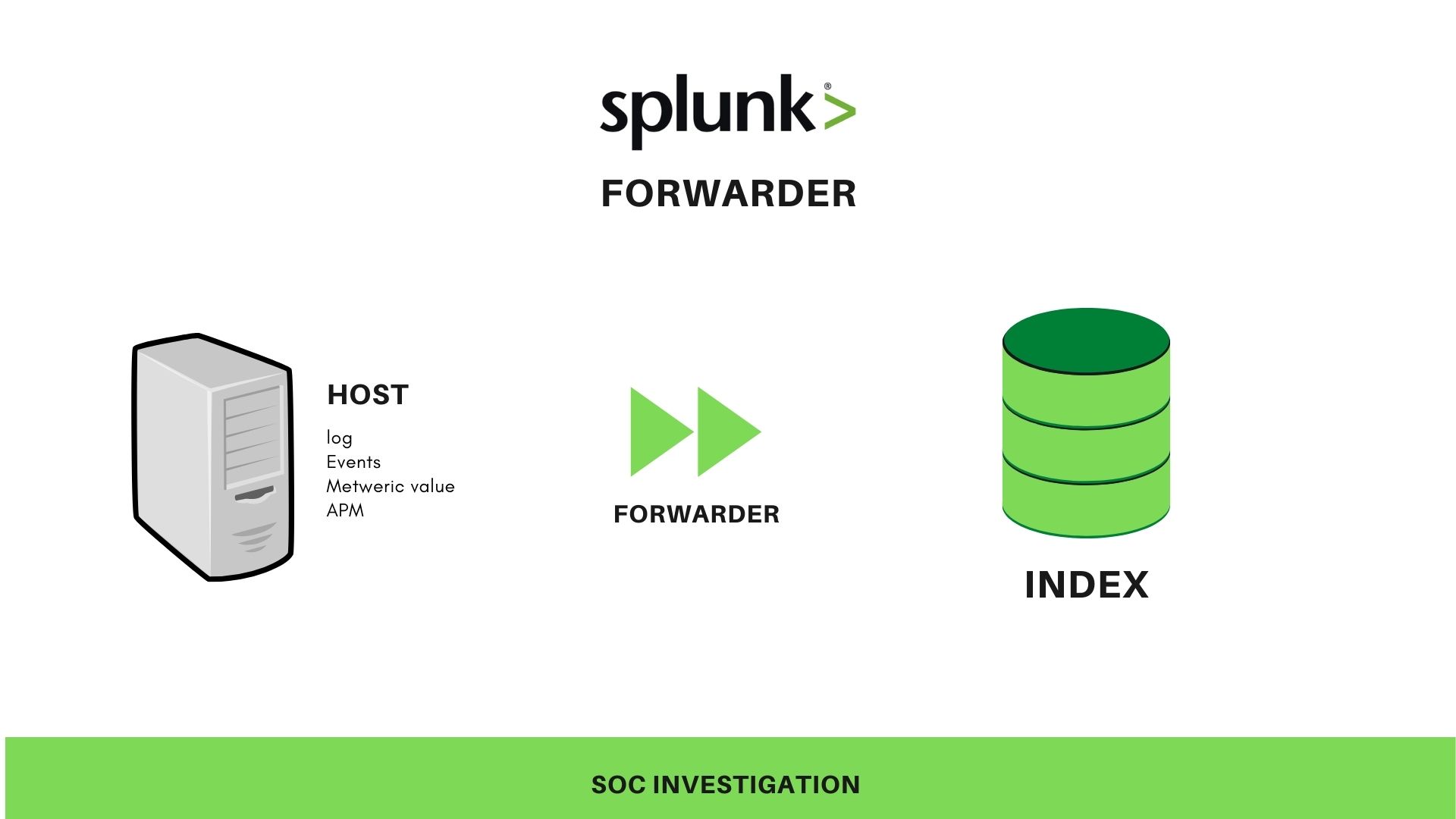
Types of forwarders:
- Universal forwarder
Universal forwarders are being used to simply forward RAW log from the host to the index, the process was too quick.
- Heavy forwarder
A heavy forwarder does parsing and indexing at the source and also intelligently routes the data to the Indexer, this process may be time-consuming but it has a clear insight.
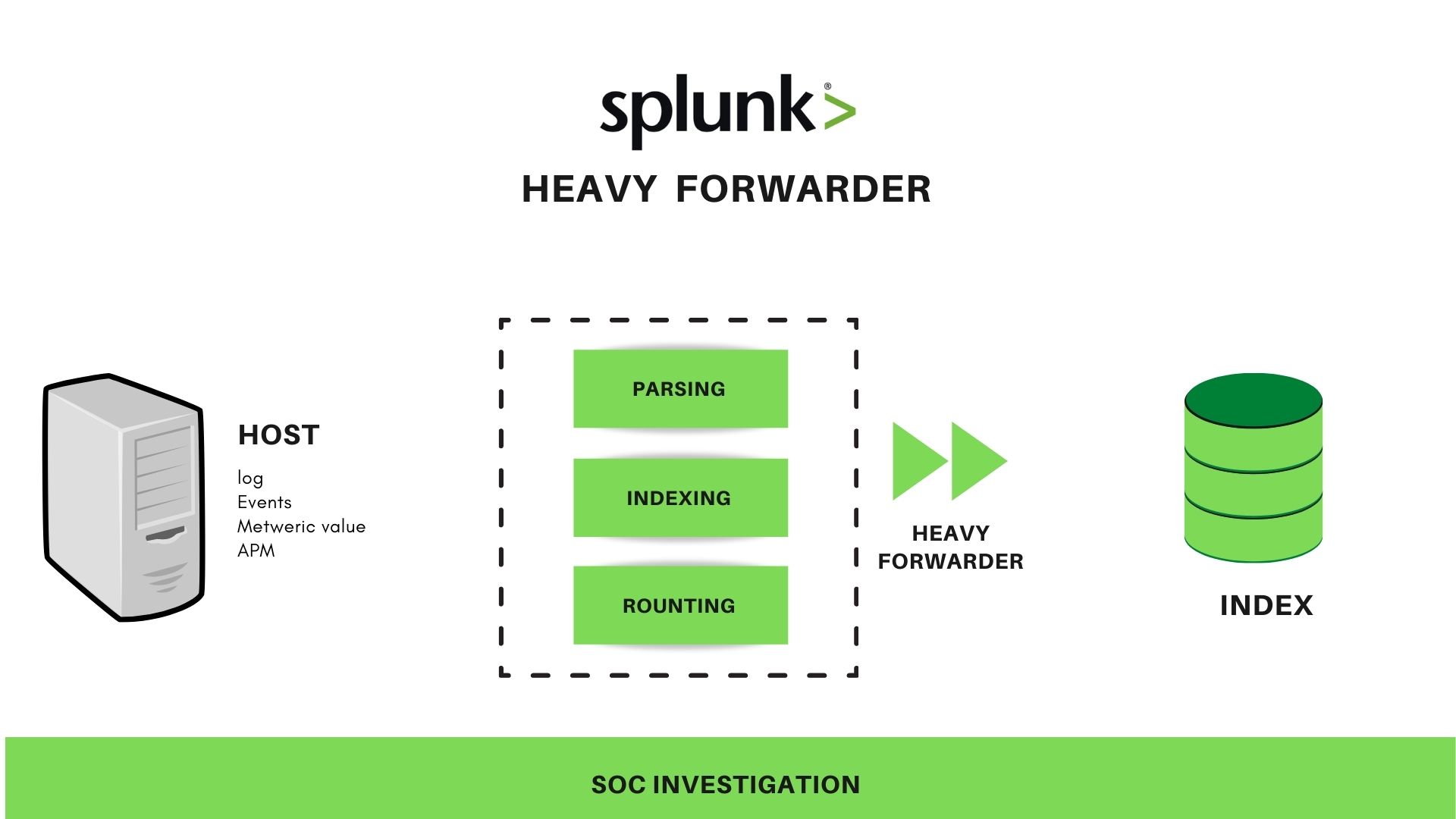
SPLUNK Index
A centralized component of Splunk is used for indexing and storing data received from the forwarder, generally, data indexes are used to quickly locate and access the data in a database.

Similarly, Splunk collects data from forwarders and converts it into a single event. While indexing, Splunk enhances the data in various ways, including by:
- Separating the datastream into individual, searchable events.
- Creating or identifying timestamps.
- Extracting fields such as host, source, and sourcetype.
- Performing user-defined actions on the incoming data, such as identifying custom fields, masking sensitive data, writing new or modified keys, applying breaking rules for multi-line events, filtering unwanted events, and routing events to specified indexes or servers.
Indexer vs Indexer cluster
Indexer: The indexer is the component that creates and manages a collection of indexes, an organization can manage multiple indexes across their enterprise, hence it can be managed under an indexer

Indexer Cluster: The technique which provides redundant indexing and searching capability, if in case of failover from one peer node[index] it automatically starts storing in others.
Features of Indexer Cluster
- A single manager node to manage the cluster. The manager node is a specialized type of indexer.
- Several peer nodes that handle the indexing function for the cluster, indexing and maintaining multiple copies of the data and running searches across the data.
- One or more search heads to coordinate searches across all the peer nodes.
Also Read: Soc Interview Questions and Answers – CYBER SECURITY ANALYST
Search Head
A GUI which allows users to investigate the collected data using some SPLUNK queries, it is a component that revokes back required data in the massive collected database [index]. Generally, the search head generates the request to all the indexes and merges the results, and sends them back as a result.
Features in SPLUNK
- Indexing
- Search head
- Alerts
- Dashboard
- Pivot
- Reports
- Data model
Conclusion
Splunk has become an essential tool for real-time monitoring and analysis among many security experts. In an upcoming blog, we are going to discuss the key feathers, implementation, and analysis in SPLUNK.